Awkの基礎
目次
※(gawk)の表記は gawk で使用できることを示す。 gawk(GNU Awk) のマニュアルはこちら。
awk の実行形式
1awk [-v var=value] [-Fre] [--] 'pattern { action }' var=value datafile(s)
2awk [-v var=value] [-Fre] -f scriptfile [--] var=value datafile(s)
- datafile(s) の末尾の (s) は複数ファイルを扱えることを示す。スクリプト内ではシステム変数 FILENAME を使って処理中のファイルを確認できる。
- 入力ファイルが指定されないか、- が指定された場合は、標準入力から読み込まれる。
- -F はフィールドセパレータを設定する。
- -v は、スクリプト実行前に変数 var に value を設定する。変数代入文ごとに -v を指定すること。
- -v で指定する変数代入分はスクリプトの前方に指定する。-v を指定しないものはスクリプトの後方指定。
- -- はコマンドラインオプションの終わりを示す。例えば datafile の名前の先頭にもし - がついていた場合、普通ならコマンドラインオプションとして解釈されるが、-- を使うことで正しくファイルとして解釈される。
- スクリプトの後ろに指定された変数(システム変数も含む)の値もスクリプトに渡せるが、datafile からの一行目が読み込まれるまでは利用できない。
- value には固定値のみならず、シェル変数やコマンド出力結果を設定することもできる。var=$value や var=`command` のように。
- 指定した変数はファイル名が識別されるまで、コマンドラインに登場した順に評価される。
例えばawk 'pattern{action}' var1=value1 datafile1 var2=value2 datafile2と書いた場合、datafile1 の処理中は var2 の設定内容 value2 を利用できない。
awk スクリプトの構造
1BEGIN{ action }
2pattern1{ action1 }
3pattern2{ action2 }
4 .
5 .
6 .
7patternN{ actionN }
8END{ action }
- BEGIN で始まるルーチンは、最初の入力行の処理前に一度だけ実行する。
- BEGIN と END の間のルーチンは、各入力行に対して実行される。メイン入力ループと呼ばれる。
- END で始まるルーチンは、全ての入力行の処理後に一度だけ実行する。
- 上記のルーチンは、それぞれ省略可。
awk スクリプトの書き方
1pattern{ action }
- action は pattern にマッチする入力行に対して実行される1個以上の文。pattern を指定しなければ action は全ての入力行で実行される。
- pattern には以下を指定可能。
/regular expression/relational expression(条件式)pattern, pattern - pattern を変数で指定できる。コマンドラインから渡す変数を pattern に使用すれば、動的に pattern を変化させることが可能となる。
- 古いAwkの場合、pattern に変数を使用すると、その内容次第でエラーとなる可能性がある。pattern に単純な値(数値や文字列)が設定されていると、環境によってはエラーになるようだ。(リンク先の2つ目の回答事例を参照)
例えばflg{action}の代わりにflg != 0{action}のように条件式を使えばOK。 - action を省略した場合、
printが暗黙の action となる。 - awk スクリプトの行は、改行かセミコロンで終了する。セミコロンを使えばワンライナーで書ける。
- コメントは # から行端まで。
- スクリプト中に関数を定義できる。
function name(parameter list){ statements }
name と ( の間に空白を入れるのは不可。
1# example
2echo -e 'ab\n\nef' | awk '/^$/{print NR}' # 2 を出力
3echo -e 'ab\n\nef' | awk 'NR==3{print}' # ef を出力
エスケープシーケンス・演算子
- エスケープシーケンス
\n(改行)\r(復帰)\t(水平タブ)\ddd(1〜3桁の8進数ASCIIコード値)
\ddd を使うケース:コマンドラインでスクリプト内にシングルクォート「'」を書く場合、スクリプトの囲み文字と区別できなくなるため直接書くことができない。代わりに「\47」を使う。
ex) awk 'BEGIN{system("sed \47/b/y/\47 a.txt")}'
ex) printf("%\47d", var) - 文字列連結の演算子は、空白。
- 算術演算子
+(加算)-(減算)*(乗算)/(除算)%(剰余)^(累乗) - 代入演算子
++(1 を加算)--(1 を減算)+=(加算結果を代入)-=(減算結果を代入)*=(乗算結果を代入)/=(除算結果を代入)%=(剰余結果を代入)^=(累乗結果を代入) - 関係演算子
<(未満)>(超過)<=(以上)>=(以下)==(等しい)!=(等しくない)~(マッチする)!~(マッチしない) - 論理演算子
||(OR))&&(AND)!(NOT) - 三項演算子
expr ? action1 : action2(条件式 expr が真の場合は action1 の実行結果を返し、偽の場合は action2 の実行結果を返す) - in 演算子
item in arrayにより array[item] が存在すれば 1 、存在しなければ 0 を返す。
フィールドセパレータ(デリミタ)
- "$0"は入力レコード全体、"$1"は最初のフィールド、"$2"は2番目のフィールド、・・・となる。
- フィールドセパレータ (デリミタ)はデフォルト空白。
コマンドラインオプション -F で変更可。カンマにする場合-F,、タブにする場合-F"\t"と書く。エスケープ文字を使う時は " で囲む。
スクリプトでも指定可。システム変数 FS を使う。カンマにする場合はFS=","と書く。 - デリミタに複数文字を指定すると、正規表現として解釈される。
FS="\t+"は連続したタブを一つのデリミタとしてフィールド分割される。 - 空行で区切られた複数行をまとめて処理したい場合、
FS = "\n"; RS = ""と設定することで、スクリプト中ではその複数行を1行と見做して処理できる。元の各レコードは各フィールドとなる。ページ下端の例題2を参照のこと。
変数・システム変数
- 変数の宣言、初期化は不要。初期化されていない変数の値は、文字列としては空文字列、数値としては0になる。
- 変数名には英数字とアンダースコアが使用可。先頭に数字は使えない。大文字小文字は区別される。
- システム変数
FS:フィールドセパレータ(デリミタ)。デフォルトは空白OFS: 出力用フィールドセパレータ。デフォルトは空白。print文でパラメータをカンマ区切りで指定する時に効いてくる。printfでは使えない(たぶん)。RS: レコードセパレータ。デフォルトは改行。空の値が設定されている場合、空行がセパレータとなる。ORS: 出力用レコードセパレータ。デフォルトは改行。print文で使う。printfでは使えない(たぶん)。FIELDWIDTHS(gawk):固定幅分割の区切り位置を示す空白区切りの数字リスト。FSは無効化される。電文などを区切るときに便利。NF: カレントレコードのフィールド数。最後のフィールドを参照するときに便利。NR: カレントレコード番号。複数ファイルが指定された場合は通し番号となる。FNR: 入力ファイルごとのカレントレコード番号ARGC: コマンドライン引数の数ARGV: コマンドライン引数の配列FILENAME: カレントファイル名CONVFMT: 数値が文字列変換される時に適用されるフォーマット指定子(デフォルト %.6g) (POSIX)OFMT: 数値の出力形式 (%.6g)RLENGTH: match() でマッチした文字列長RSTART: match() でマッチした文字列の先頭位置ENVIRON: 環境変数の配列SUBSEP: 擬多次元配列インデックスの区切り文字(デフォルト \034)IGNORECASE(gawk):0 でない場合はパターンマッチングと文字列比較で大小文字が区別されない。FPAT(gawk):レコード内のフィールド自体を表す正規表現。 設定するとFS は無視される。
◆ FPAT の例 (gawk)
1$ echo 'aaa,"bbb,ccc",ddd' | gawk -v FPAT='([^,]+)|(\"[^\"]+\")' '{print $1,$2,$3}'
2aaa "bbb,ccc" ddd
◆ IGNORECASE の例 (gawk)
1$ echo -e "abc\nABC" | gawk '/a/' IGNORECASE=0
2abc
3$ echo -e "abc\nABC" | gawk '/a/' IGNORECASE=1
4abc
5ABC
◆ FIELDWIDTH の例 (gawk)
1$ echo "1234567890" | gawk 'BEGIN{FIELDWIDTHS="4 3"}{for(i=1;i<=NF;i++)print $i}'
21234
3567
◆ ARGC, ARGV, FILENAME, NR, FNR, NF の例
1# example
2BEGIN{
3 printf( "ARGC : %s\n", ARGC )
4 for(i=0;i<ARGC;i++)
5 printf( "ARGV[%d] : %s\n", i, ARGV[i] )
6
7 print
8 printf( "%8s : %3s : %3s : %3s : %s\n",
9 "FILENAME", "NR", "FNR", "NF", "LINE")
10}
11{
12 printf( "%-8s : %3d : %3d : %3d : %s\n",
13 FILENAME, NR, FNR, NF, $0 )
14}
上記の awk スクリプト(sample.awk)を使って ARGC, ARGV, FILENAME, NR, FNR, NF の内容を確認してみる。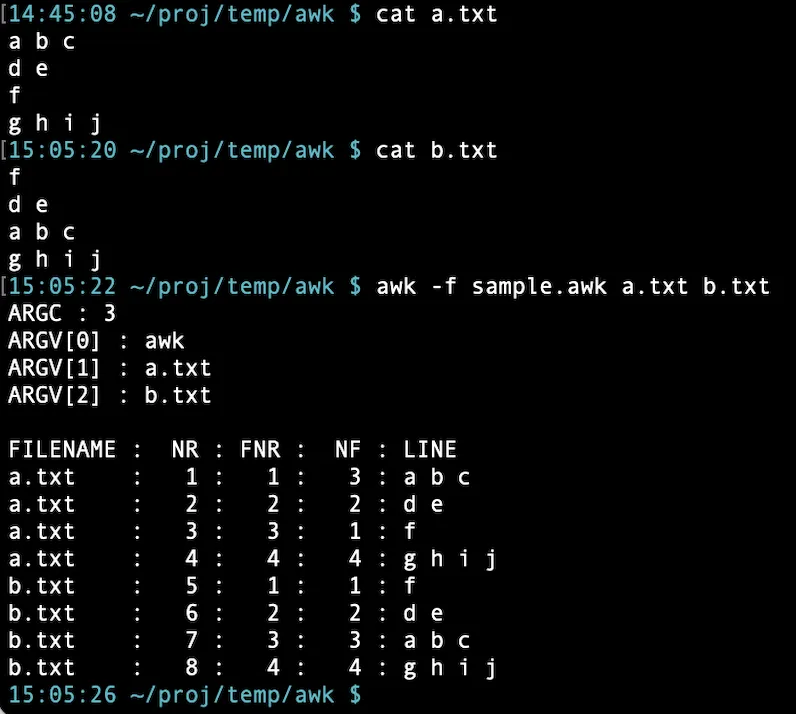
制御文
1### 条件文 ##########
2if( expression )
3 action1
4[else if( expression )
5 action2]
6[else
7 action3]
8
9if( expression ) action1
10[else if( expression ) action2]
11[else action3]
12
13if( expression ) action1; [else if( expression ) action2;] [else action3]
14
15### ループ文1 ##########
16while( condition )
17 action
18
19while( condition ) action
20
21### ループ文2 ##########
22# action が少なくとも1回は実行される
23do
24 action
25while( condition )
26
27do action
28while( condition )
29
30do action; while( condition )
31
32### ループ文3 ##########
33# init: 初期値、test: 条件式、incr: カウンタインクリメント
34for( init; test; incr )
35 action
36
37for( init; test; incr) action
- アクションが複数の文で構成される場合は {} で括る。
- expression が真の場合に action が実行されるが、ここでの真は(ゼロ以外 or 空以外)と同等である。よって、if ( x ) のような書き方も可能である。
breakで while, for, do のループから脱出するcontinueで while, for, do ループの次の繰り返しを開始する。
配列
- 配列要素は
array[index]で参照・代入できる。 delete array[index]
配列の要素を削除する。全要素を削除したければ delete array もしくは for(index in array) delete array[index] 。split( str, arr, sep )
文字列 str をセパレータ sep を用いて分解し、配列 arr に格納する。戻り値は配列の要素数。sep 未指定時は FS の値が使用される。- awkの配列は連想配列。index に数値を指定しても文字列に変換される。
- 配列用のループ構文。ここでの item は配列のインデックスだが、"item" という名前がよく使われるらしい。
1for (item in array)
2 array[item]への命令
if(item in array)により、インデックス item の存在チェックができる。チェックするのはインデックスであり要素の値ではない。- 多次元配列はサポートしていないが、類似の参照方法が可能。例えば array[2, 4] のように書ける(ここでは擬多次元配列と呼ぼう)。インデックスは 2 と 4 の間にシステム変数 SUBSEP を挟んで結合された文字列に変換される。SUBSEP は特に指定しなければ \034 になり、インデックスは "2\0344" という形で保持される。
- 擬多次元配列は通常の配列同様
if ((i,j) in arry)のように要素チェック可能。またfor (item in array)のような配列特有のループも可能。ただし、ここのインデックス要素を参照するには split() と SUBSEP を使って分ける必要がある。split(item, subarr, SUBSEP) - awk の多次元配列は擬似的であることが分かる例
1# 添字[1,1]が異なるSUBSEPの値で別個に保管されている([1,1]の指定で一意の値を取れない)
2$ awk 'BEGIN{
3 SUBSEP="^"
4 arr[1,1]="A"
5 SUBSEP="@"
6 arr[1,1]="B"
7 for(item in arr)print item, arr[item]
8 print arr[1,1]
9 SUBSEP="^"
10 print arr[1,1]
11}'
121@1 B
131^1 A
14B
15A
16$
awkの関数・コマンド
close( filename-expr ), close( command-expr )
ファイルやパイプをクローズする。exit [ expr ]
新しい入力行を読まず、制御が END ルーチンに移る。END ルーチンがなければそのまま終了する。expr が awk の戻り値となる。
ex) awk 'BEGIN{exit(9)}'; echo $? # 9が出力されるgetline [ var ] [ <"file" ], command | getline [ var ]
処理中のファイルから次行を読み込む。または、指定されたファイルやパイプで渡された結果を一行読み込む。1番目の形式は file から入力を読み込み、2番目の形式は command(外部コマンド)の出力を読み込む。 入力行は $0 に代入されてフィールドに分解され、NF, NR, FNR が設定される。 var が指定されると、読み込み行が var に設定され、$0 は変更されない。すなわちカレント行は変化しない。 レコードの読み込みに成功したら 1 、ファイル末尾に達したら 0 、エラーが発生したら -1 を返す。 next と異なり、制御はスクリプト先頭に戻らない。
ex) getline < "dir/data" # dir ディレクトリ内の data ファイルを一行だけ読み込む
ex) getline < "-" # 標準入力から読み込む(入力待ちになる)
ex) "who am i" | getline # 外部コマンドの出力結果を一行だけ読み込む
ex) while("ls -1" | getline) # 外部コマンドの出力結果を繰り返し読み込むsub( r, s, t )gsub( r, s, t )
sub は、文字列 t で、正規表現 r にマッチする最初のパターンを s に置換する。 gsub は、マッチするもの全てをグローバルに置換する。 戻り値は置換した数。t が未指定の場合は行全体($0)が対象となる。
ex) gsub(/UNIX/, "LINUX")
sed と同様、置換文字列に "&" を入れると、正規表現にマッチした文字列に置き換えられる。gensub( r, s, h, t )(gawk)
文字列 t で、正規表現 r にマッチする h 番目のパターンを s に置換する。 h が g または G で始まる場合はグローバル置換となる。 戻り値は置換後の文字列で、置換対象の s は変更されない。 sed と同様に()で表現したサブマッチを\nで使いまわせる。
ex) echo "20221015" | gawk '$0 = gensub(/(.{4})(.{2})(.{2})/, "\\2-\\3-\\1", 1)' # 10-15-2022index( str, substr )
文字列 str に対して substr で検索し、見つかった位置を返す。先頭なら1。length( str )
文字列 str の長さを返す。str の指定がなければ行全体($0)が対象。match( s, r )
文字列 s の中から正規表現 r で指定されたパターンを探し、一致する先頭部分の位置を返す。 マッチしなければ 0 を返す。システム変数 RLENGTH, RSTART にそれぞれマッチした文字列長、先頭位置がセットされる。引数の順序は ~ 演算子と同じであることに注意してください: s ~ rmatch( s, r, [, a] )(gawk)
配列 a が存在する場合はクリアされ、 a の 0 番目の要素が正規表現 r に一致する文字列の部分全体に設定される。 r に括弧が含まれている場合、配列の整数インデックス付き要素は、対応する括弧で囲まれた部分式に一致する文字列に設定される。 さらに、一致した各部分式の開始位置 ( "start" ) と長さ ( "length" ) を提供する多次元インデックスを使用できる。 左記以外は match( s, r ) と同じ。
1$ echo foooobazbarrrrr |
2> gawk '{ match($0, /(fo+).+(bar*)/, arr)
3> print arr[1], arr[2]
4> print arr[1, "start"], arr[1, "length"]
5> print arr[2, "start"], arr[2, "length"]
6> }'
7foooo barrrrr
81 5
99 7
next
次の入力行を読み、スクリプトの先頭に制御をジャンプする。print [ output ] [ dest ]
output を標準出力に送り、ORS(出力用レコードセパレータ)を出力する。 output はOFS(出力用フィールドセパレータ)で区切られる。 dest は出力をファイルやパイプに送る場合の式で、省略可能。 「>"file"」で file に上書きされ、「>>"file"」で file に追加される。 file がなければ作成される。 "| command" で出力は command にパイプで渡される。printf( format [ , list ] ) [ dest ]
C言語由来の出力文。フォーマットを指定できる。 format はフォーマット指定子と定数で構成される文字列。list はフォーマット指定子に対応した引数リスト。 dest は print 文と同様。rand()
0 から 1 までの間の乱数を生成する。 乱数ジェネレータに srand() でシードを与えない限り、この関数はスクリプトを実行するたびに同じ数値パターンを返す。return [ expr ]
ユーザ定義関数の終わりで、関数を終了して式の値を返すときに使われる。sprintf( format [ , expr ] )
printf のフォーマット指定子に従って書式化した文字列を返す。format, expr の説明は printf と同じ。srand( expr )
expr を使って乱数ジェネレータようの新しいシードを設定する。デフォルトはその日の時刻。以前のシードを返す。substr( str, beg, len )
文字列 str で位置 beg から文字数 len の分だけ、部分文字列を返す。len が未指定の場合は、行末まで返される。system( command )
command(外部コマンド)を実行し、その終了ステータスを返す。 command の出力は awk スクリプト中では処理できない。 command の出力はcommand | getlineを使ってスクリプトに読み込む必要がある。systime()(gawk)
現在時刻をエポック(1970年1月1日午前0時0分)からの秒数で返す。strftime( format, timestamp )(gawk)
format に従って timestamp の形式を変換した値を返す。 timestamp の形式は systime() の返却値と同じで、未指定時は現在時刻となる。 format はフォーマット指定子で表現された文字列。 format 未指定時は date コマンドに似た出力形式となる。
ex) awk 'BEGIN{print strftime("%Y-%m-%d %H:%M:%S")}' # 2022-10-15 16:23:26tolower(str)
文字列 str の全ての大文字を小文字に変えて返却する。toupper(str)
文字列 str の全ての小文字を大文字に変えて返却する。
ユーザ定義関数
1function name (parameter-list) {
2 statements
3 return [expression] # return 文や expression は必須ではない
4}
- 関数定義はパターン-アクションルールを書けるところなら、スクリプトのどこにでも置ける。
- {}や()の前後に改行を入れても入れなくても可。
- parameter-list はカンマ区切り。
- ユーザ定義関数を呼び出すときは、関数名 name と "(" の間に空白を入れてはならない。(この制約は組み込み関数には当てはまらない)
- parameter-list はローカル変数となる。
- 関数内で定義された変数はグローバル変数となる。
- parameter-list の中でローカル変数を宣言できる。この変数は関数呼出時に指定されなくても関数内では使用できる。慣習上、ローカル変数は実パラメータと複数の空白でもって区切ることになっている。
ex) function name(param1, param2, param3, param4){ statements } - パラメータに配列を指定した場合、配列への参照(ポインタ)が渡される。配列以外の変数と異なり、コピーが渡されるのではない。
- ユーザ定義関数を独立したファイルに積み上げてライブラリとし、awk 実行時に -f オプションを複数使ってそのライブラリを利用できる。
ex) awk -f lib.awk -f main.awk infile # lib.awk がライブラリ
1$ cat sample.txt
2aaa=100 bbb=200 ccc=300
3aaa=150 bbb=220 ddd=400 ccc=200
4aaa=160 ccc=140 bbb=250 eee=600 fff=200
5
6# sample.txtよりaaa, bbb, cccの順に出力するawk
7$ awk '
8function ex(x){
9 for(i=1;i<=NF;i++)
10 if($i~x)
11 return $i
12}
13{print ex("^aaa"), ex("^bbb"), ex("^ccc")}
14' sample.txt
15aaa=100 bbb=200 ccc=300
16aaa=150 bbb=220 ccc=200
17aaa=160 bbb=250 ccc=140
フォーマット出力とフォーマット指定子
1printf( format[, arg] )
2formatの形式: %-width.precision specifier
- width は出力フィールド幅。指定すると右詰となる。「-」指定で左詰になる。
- precision は小数点の右側に表示される桁数。浮動小数点形式で使われる。
- width と precision に * を使うと、printf や sprintf の引数リストの値を利用して動的に指定できる。
ex) printf("%*.*f\n", 5, 3, var) - specifier(フォーマット指定子)
c(ASCII文字)d(10進整数)f(浮動小数点形式)s(文字列) - 数値の整数部を3桁ごとのカンマ区切りで出力したい場合、
printf("$\47d", var)などと書く。47 は「'」のASCIIコード8進値。format に直接「'」を書くことは不可。「'」は awk のコマンドラインでスクリプトの囲み文字として使用されるため。
例題1
任意のディレクトリ配下のファイル数・ディレクトリ数・リンク数を出力し、さらにファイルサイズの合計を出力するような awk スクリプトを考えてみる。ls コマンドの実行結果をインプット情報とする。
以下は、あるディレクトリの ls コマンドの実行結果。なお、オプションの a は「.」から始まる隠しファイルを出力、F は実行ファイルやディレクトリ・シンボリックリンクを識別する文字などを出力、R はディレクトリがあれば再帰的に出力するものだ。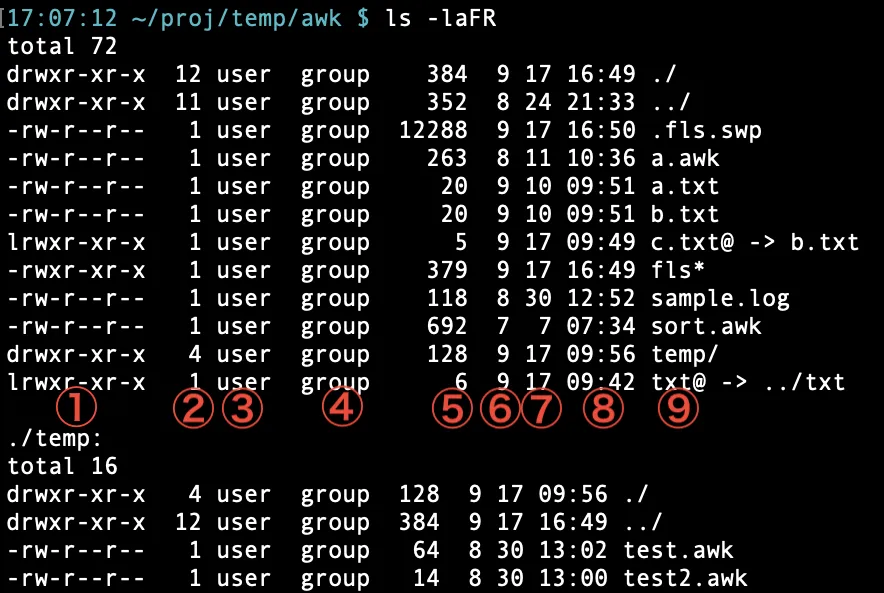
作成した awk スクリプトを組み込んだコマンド fls を実行した結果が下図。これが期待結果となる。
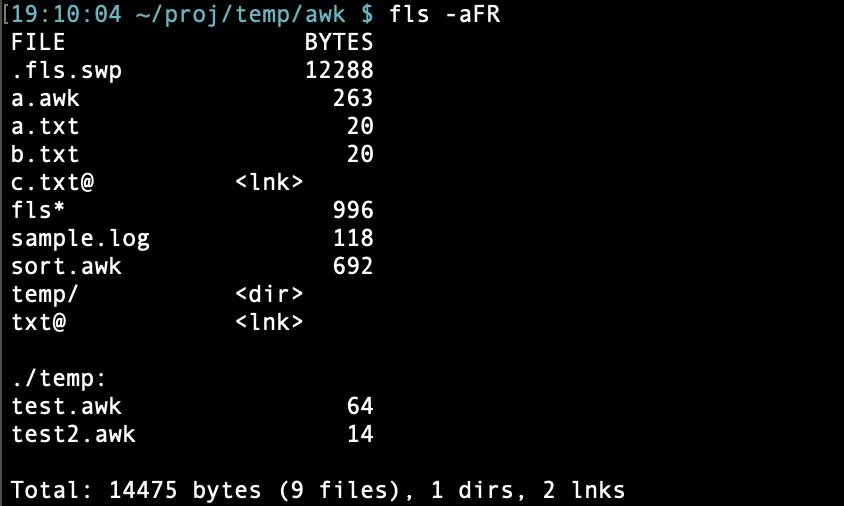
以下が awk スクリプトを組み込んだコマンド fls の中身。1行目の $* は fls 実行時の引数が展開される。
1ls -l $* | awk '
2BEGIN {
3 # ヘッダー出力
4 printf("%-15s\t%10s\n", "FILE", "BYTES")
5}
6# -l 指定時の出力結果フィールド数は9。9でない行はファイルの詳細情報の行ではない。
7# 行頭が - から始まるものは通常のファイル
8NF == 9 && /^-/ {
9 sum += $5
10 ++filenum
11 printf("%-15s\t%10d\n", $9, $5)
12}
13# 行頭が d から始まるものはディレクトリ。./ と ../ は無視する。
14NF == 9 && /^d/ && $NF !~ /\.+\// {
15 ++dirnum
16 printf("%-15s\t<dir>\n", $9)
17}
18# 行頭が l から始まるものはシンボリックリンク
19/^l/ && $0 ~ / -> /{
20 ++lnknum
21 printf("%-15s\t<lnk>\n", $9)
22}
23# -R 指定時に出力されるディレクトリのヘッダーに対する処理
24/^$/{print}
25$1 ~ /^\..*:$/ {
26 printf("%-15s\n", $0)
27}
28END {
29 print ""
30 # ファイルサイズ合計とファイル数、ディレクトリ数、リンク数を出力
31 printf("Total: %d bytes (%d files), %d dirs, %d lnks\n", sum, filenum, dirnum, lnknum)
32}'
例題2
下図は都道府県別の人口リストであり(途中まで表示)、ブロック別に空行で区切られている。この例題では、awk スクリプトにより、ブロックの平均人口がスクリプトパラメータで渡された人口以上のブロックを、ブロックまるごと表示させる。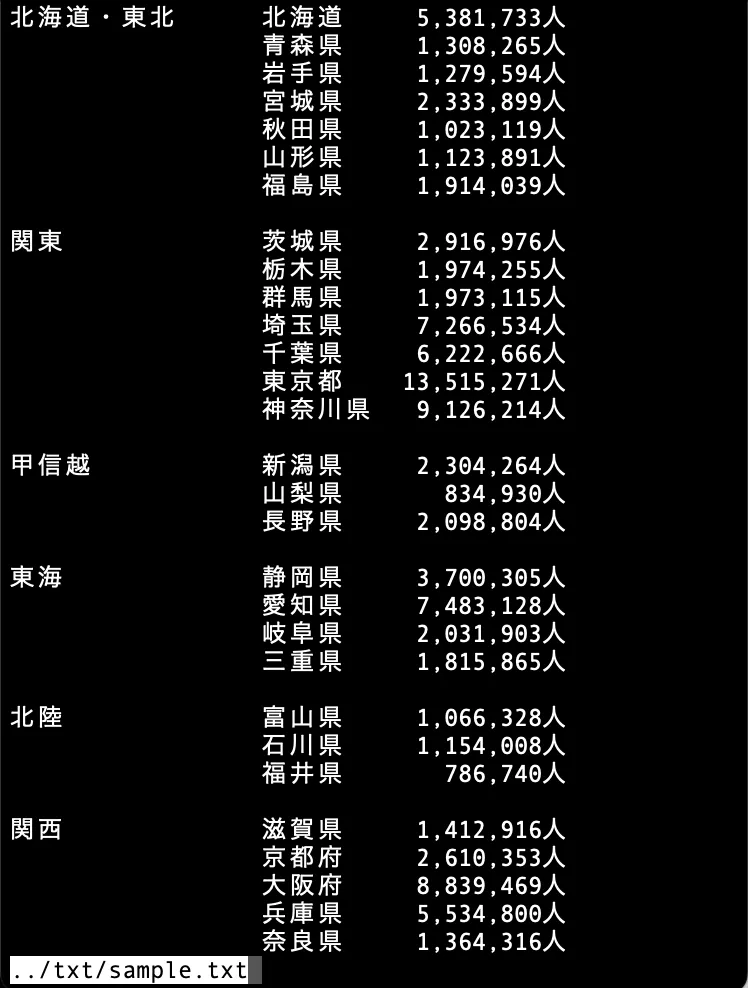
期待結果は下図。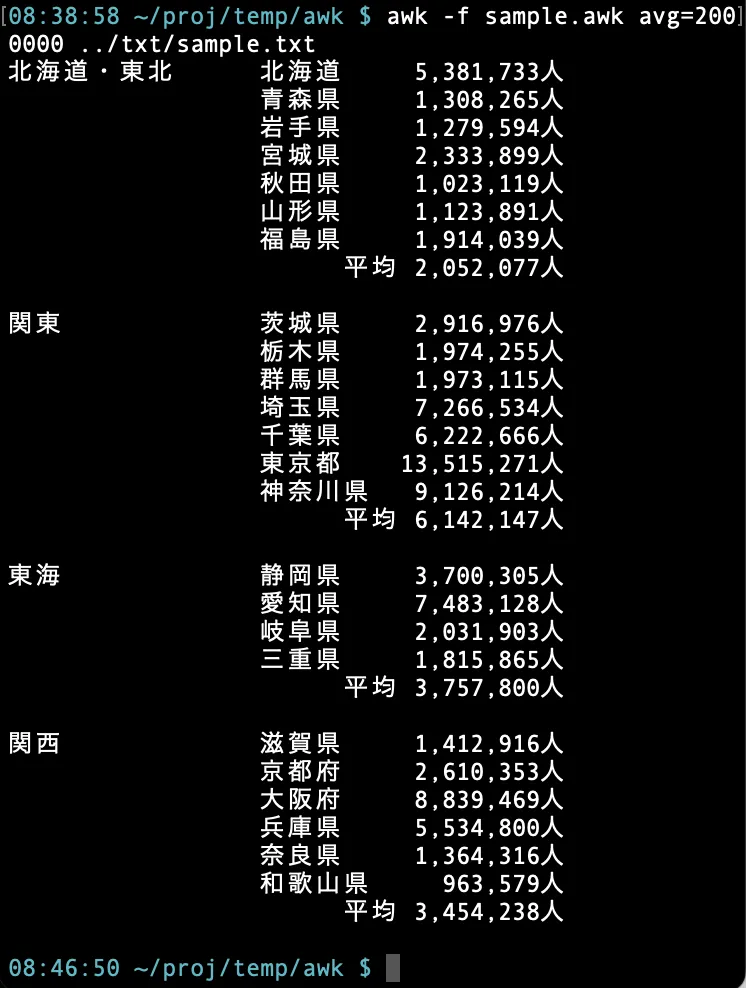
コマンドラインから awk -f sample.awk avg=2000000 ../txt/sample.txt を実行してる。スクリプト内部では、変数名 avg(2000000が格納されている)を使用することができる。sample.awk の中身は以下。
1BEGIN{ FS="\n"; RS="" }
2{
3 sum = 0 # 人口合計
4 i = 1 # フィールドカウンタ
5 while ( i <= NF ){
6 wk = $i
7 gsub( /[^0-9]/, "", wk )
8 sum += wk
9 i++
10 }
11 if ( sum / NF > avg ) {
12 print
13 printf( "%24s%s %\047d人\n\n", " ", "平均", sum / NF )
14 }
15}
以下で要点を解説する。
- BEGIN ルーチンでフィールドセパレータを改行コード「\n」、レコードセパレータを空としている。これにより、スクリプト内では一つのブロックが1行と見做され、かつ、元の各都道府県の行がフィールドと見做される。
- メイン入力ループでのフィールドは sample.txt の各都道府県の行に対応している(行がフィールドとなる!)。while ( i <= NF ) により、ブロックの最初の都道府県から最後の都道府県まで繰り返すことになる。
- 7行目の gsub により数値以外は全て削除される。すわなち人口の数値だけが変数 wk に残る。
- 11行目でブロックの平均人口( sum / NF )と、スクリプトのパラメータとして受け取った avg の値を比較している。NF はフィールド数だが、ブロック内の都道府県の数とイコールだ。
- 12行目で処理中の1行(1ブロック)を出力している。スクリプト内ではブロックをまるごと1行と見做して処理したが、出力データを受け取る外側のプロセスに影響しないので、元の sample.txt の1ブロックがそのまま表示される。