Sedの高度な使い方・・・テストコマンド「t」で繰り返し置換する
この記事でわかること。
・sedスクリプトをワンライナーで記述する方法
・sedスクリプトをワンライナーで記述する方法(BSE sedの場合)
・sedのテストコマンド「t」の使用方法
sedスクリプトをワンライナーで記述する方法
複数のコマンドをワンライナーで記述するには、コマンドの後ろにセミコロンをつけて次のコマンドを繋げれば良い。
以下はaddressの指定がないので全ての行に対して適用されるコマンドリストだが、
1command1
2command2
3command3
これを次のように書ける。
1command1;command2;command3
特定のaddressに対してコマンドリストを適用する場合は、コマンドリストを{}で括って記述できるが、
1[address]{
2 command1
3 command2
4 command3
5}
これを1行で記述することもできる。
1[address]{command1;command2;command3;}
なお,最後に記述した編集コマンドと同じ行に「}」を記述する場合は,コマンド名の後ろに「;」を記述する必要がある。
sedスクリプトをワンライナーで記述する方法(BSE sedの場合)
macターミナルなどBSD系の場合、sedコマンドの区切り文字としてセミコロンが使えないようだ。
代替方法は、-e によるコマンドを繰り返し書くか、またはワンライナーに拘らずに改行することだ。
1sed -e 'command1' -e 'command2' -e 'command3' targetfile
2sed -e '[address]command1' -e '[address]command2' -e '[address]command3' targetfile
3sed '[address]{
4 command1
5 command2
6 command3
7}' targetfile
泥臭いと言われるかもしれないが、環境に依存せずどこでも使える方法と言える。
sedのテストコマンド「t」の使用方法
アドレスで指定された行に対して置換が成功した場合に、制御はスクリプトのラベル位置の下にジャンプする。
ラベルを指定しなければ、制御はスクリプトの末尾にジャンプする。
1[address]t[label]
例えば、次のようにスクリプトを書いた場合、置換コマンドsが成功すれば(置換が実施されれば)、tコマンドでラベルtopに処理がジャンプする。
すなわち、sコマンドが成功するあいだ、繰り返しcommand1とsコマンドが実行される。
このように通常は上から下に流れる制御フローを変更することができる。
そしてsコマンドが不成功になったら、command2が実行される。
1:top
2command1
3s/pattern/replace/
4ttop
5command2
仮にラベルの位置を下方に指定すれば、途中のコマンドをスキップさせることもできる。
実践例
QAサイトにて以下の質問あり。
テキストファイルdata.txtの内容が以下で、()内の「,」のみを別の文字に置き換えるにはどうすれば良いか・・・との質問。
10","1","([1,2,3,4,5,6,7])","1","
21","1","([9,1,2,3,4,5,7])","1","
32","1","([1,3,3,2,1,1,7])","1","
43","1","([5,2,2,4,5,6,7])","1","
いくつか示された回答のうちの一つが以下。sedを使ってカンマを縦棒(パイプ)に置換している。
1sed -e ':a;s/^\(\([^",]*\|"[^"]*"\)*\),/\1|/;ta' data.txt
この解釈を試みるが、その前にエスケープが多用されていて見づらいので、拡張正規表現に直す。
1sed -re ':a;s/^(([^",]*|"[^"]*")*),/\1|/;ta' data.txt
少し見やすくなったが、ワンライナーで記述されているため、まだわかりにくい。分解表示してみる。
1:a
2s/^(([^",]*|"[^"]*")*),/\1|/
3ta
ラベルaがあって、2行目の置換が成功したら3行目でラベルへジャンプさせている。
2行目の置換が不成功になったらループを脱出して次行の処理に進む。
図のようにさらに分解して見やすくする。
緑枠線のパターンにマッチしたら、青枠線+カンマを、青枠線(点線)+パイプに置換している。
青枠線の中は、赤枠線①または②の繰り返し表現となっている。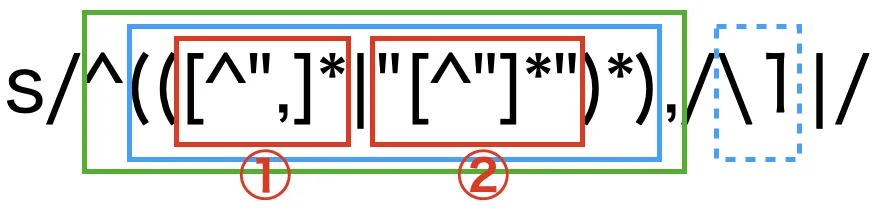
この置換コマンドをターゲットのテキストファイル data.txt に適用しよう。
data.txt の1行目は、図のようにパターンにマッチする。
そして緑枠線の右端にあるカンマがパイプに置換される。(図の下段が置換結果)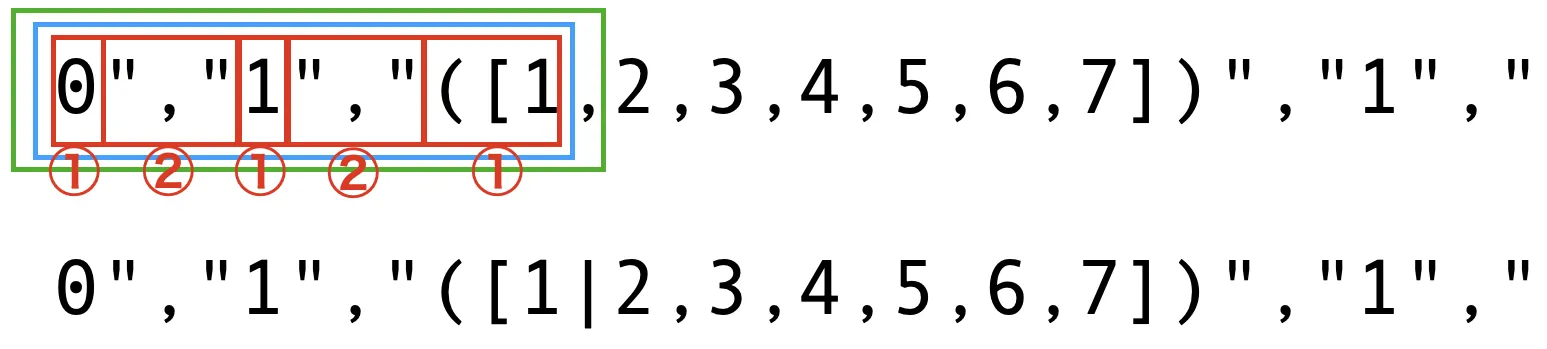
これでこの1行に対する処理は終わり・・・というわけではない。
スクリプト中のtaによりラベルaにジャンプして、再度この結果に対して置換コマンドが適用される。
もう一度適用したのが下図。緑枠線の右端のカンマがパイプに置換される。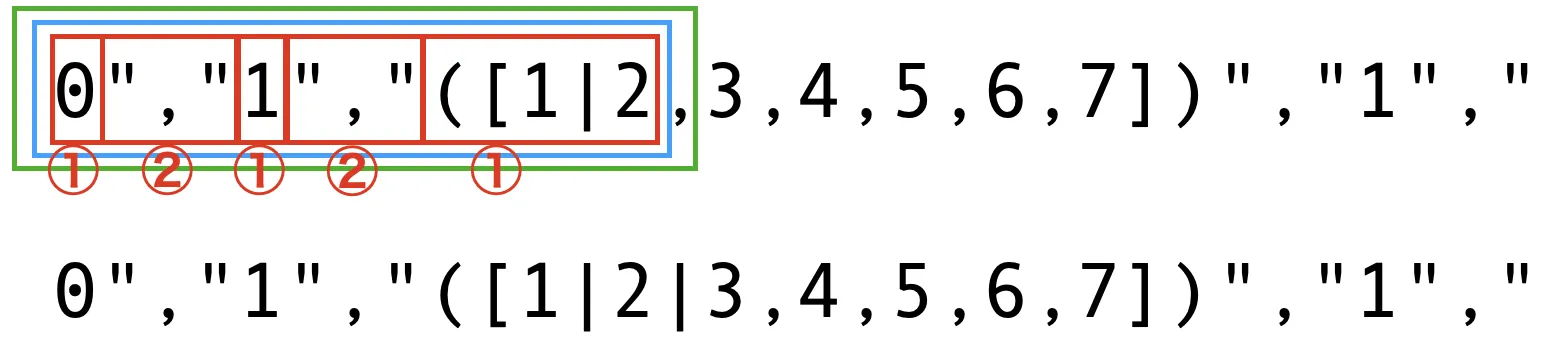
このように繰り返し置換が実行されて「6」の後ろのカンマまで置換された状態になると、置換コマンドのパターンにマッチしなくなる。ここでようやく data.txt の1行目の処理を終えて、2行目の処理に移る。

2行目以降も同様に処理することで目的の結果が得られる。
最終的な結果は以下。
10","1","([1|2|3|4|5|6|7])","1","
21","1","([9|1|2|3|4|5|7])","1","
32","1","([1|3|3|2|1|1|7])","1","
43","1","([5|2|2|4|5|6|7])","1","
macターミナルなどBSD系の環境で実行する場合は、セミコロンが使えないので、以下のように書く。
1sed -e ':a' -re 's/^(([^",]*|"[^"]*")*),/\1|/' -e 'ta' data.txt
本題は以上。
おまけ
今回の実践例ではsedコマンドを使ったが、もちろん他にも解決方法はある。
以下のshell、awkを使った例では、特に正規表現を使っていない。
1行を()をセパレータとして分割し、分割後の括弧内のカンマをパイプに置換している。
括弧内のカンマを置換するという目的からすると、上記のsedを使う方法よりも、この方法が適切だと思う。
◆shell(bash)の例
1$ cat test.sh
2#!/bin/bash
3IFS="()"
4while read a b c
5do
6 echo "$a(${b//,/|})$c"
7done
8$ cat data.txt | ./test.sh
◆awkの例
1cat data.txt | awk -F'[()]' '{gsub(",","|",$2);print $1 $2 $3}'
また、()内のカンマ以外は必ず「"」で囲まれることを前提として良いのであれば、以下の方法もある。
① ","を別文字Aに置換 → ② ,を別文字Bに置換 → ③ 別文字Aを","に置換(戻す)、というロジック・処理フローだ。
1sed -e 's/","/@/g;s/,/|/g;s/@/","/g' data.txt
2sed -e 's/","/@/g' -e 's/,/|/g' -e 's/@/","/g' data.txt # BSD系の場合
参考サイト
sedコマンド(テキスト中の文字列を置換する)
BSD sed のラベルの後ろではコマンド区切りのセミコロンが使えない