Go言語の文法基礎の備忘録
Go言語のコンパイル、実行、変数、定数、演算子、リテラルについて
◆文末のセミコロン ; は不要。
◆関数の開始波括弧 { は、funcと同じ行でないとコンパイルエラーとなる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| [波括弧の位置が正しい例]
package main
import "fmt"
func main(){
fmt.Println("Hello, World!")
}
[波括弧の位置が不正の例]
package main
import "fmt"
func main()
{
fmt.Println("Hello, World!")
}
|

◆コメントは、// または /*~*/
//以降行末までコメント。
◆コンパイル方法
「go build -o 実行ファイル名 ソースファイル名」
「-o 実行ファイル名」を省略すると、実行ファイル名が自動で決まる。
| 型 | ゼロ値 |
|---|
| bool型 | 「false」 |
| 数値型(int型、float型など) | 整数型は「0」、浮動小数点型は「0.0」 |
| String型 | 「””」空文字列 |
| 配列型 | 各要素がゼロ値の配列 |
| 構造体型 | 各フィールドがゼロ値の構造体 |
| その他の型 | nil(値が無い状態。VBAのnullと同じ) |
初期値を設定する場合は、varや型を省略可能。varを省略するときは「:=」を使う。設定する値により型が決まる。以下のex)ではint型となる。
ex) var a = 123
ex) a := 123
カンマを使うと、複数の変数に代入したり、複数の値を返す関数の戻り値をうけることが可能となる。
ex) a, b = 123, “hoge”
ex) a, b = fn()
Go言語では宣言した変数が未使用な場合、コンパイルエラーとなる。
これを回避したければ、ブランク識別子を使う。
ex) a, _ = fn() // 一つ目の戻り値しか使わない場合
◆変数の型
・論理値型は「bool」で「true」「false」の値を格納できる。
・数値型
| 型名 | 符号 | サイズ
(bit) | 説明 |
|---|
| uint8 | なし | 8 | 整数 |
| byte | なし | 8 | uint8の別名 |
| uint16 | なし | 16 | 整数 |
| uint32 | なし | 32 | 整数 |
| uint64 | なし | 64 | 整数 |
| int8 | あり | 8 | 整数 |
| int16 | あり | 16 | 整数 |
| int32 | あり | 32 | 整数 |
| rune | あり | 32 | int32の別名 |
| int64 | あり | 64 | 整数 |
| float32 | | 32 | 浮動小数点 |
| float64 | | 64 | 浮動小数点 |
| uint | なし | | 整数 |
| int | あり | | 整数 |
| uintptr | なし | | 整数。ポインタの値を格納するもの |
これらは互いに異なる型(ただしエイリアスを除く)。
・異なる型に代入するときは型変換が必要。「変換先の型(変換する値)」の形式で変換する。
var i int = 1234
var u uint32 = uint32(i)
・Go言語では文字のことをrune「ルーン」と呼ぶ。
・文字列型は「String」。整数値を文字列型に変換すると、その整数をUNICODEコードポイントとする文字を取得することが出来る。
・ユーザー定義の型を作成するには「type 型名 基になる型」
◆定数
定数の書式は「const 定数名 型 = 値または式」。型は省略可能で、「=」の右側の値・式により型が確定する。
1
2
3
4
5
6
7
8
| [型を省略した定数の例]
const i = int(123) //明示的にintの値を設定しているので、定数iの型もint型となる
const j = i*2 //jはiと同じ型になる
const x = 123
const y = int(456)
・・・
var z int = x * y //xはint型になる
|
定数を列挙する場合はグルーピングと「iota」列挙子を組み合わせると便利。グループ先頭では0を返し、呼び出される都度1ずつ増える。グループが変われば0にリセットされる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [iota列挙子の例]
const (
ZERO = iota // 0
ONE = iota // 1
TWO = iota // 2
THREE = iota // 3
)
// 以下の表記も可
const (
ZERO = iota // 0
ONE // 1
TWO // 2
THREE // 3
)
|
◆演算子
・算術演算子は、足し算「+」、引き算「-」、かけ算「*」、割り算の商「/」、割り算の余り「%」。(ビット演算、シフト演算は省略)
演算対象の型は同一でなければならない。
1
2
3
4
5
| [型変換が必要な例]
var i int32 = 123
var j int64 = 456
fmt.Println(i+int32(j)) // 演算するには型変換が必要
|
・算術演算子は「=」と組み合わせて代入できる。
ex)i += j (i = i + j と同じ。String型でも使用可)
・比較演算子は、「==」「!=」「<」「<=」「>」「>=」。戻り値は true か false 。nilの比較は「==」「!=」を使う。
・論理演算子は、AND条件「&&」、OR条件「||」、否定「!」。
◆リテラル
・文字リテラル(ルーンリテラル)はシングルクォートで囲む。 ex) a := ‘a’
・特殊文字は、バックスラッシュ「\」でエスケープすること。
\b(バックスペース)、\f(改ページ)、\n(改行)、\r(復帰)、\t(水平タブ)、\v(垂直タブ)、\(バックスラッシュ)、’(シングルクォート)、”(ダブルクォート)
・文字列リテラルは文字列をダブルクォート「”」またはバッククォート「`」で囲む。バッククォートを使うとエスケープが使えなくなるが、ソースコード上で改行ができる。
1
2
3
| [文字列リテラルの例]
a := "Hello, World!"
b := Hello, World! c := `Hello, World!`
|
Go言語のパッケージ・エクスポート・インポート
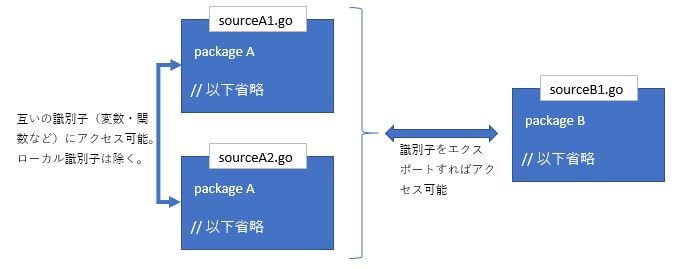
同一パッケージであれば、別ソースの識別子にアクセス可能。ただし関数内のローカル識別子はアクセス不可。
ソースファイルの先頭には、所属するパッケージを記述する。
エクスポート・インポート
異なるパッケージの識別子にアクセスする手順。
- アクセス先パッケージの識別子をエクスポートする
- アクセス元パッケージでアクセス先パッケージをインポートする
識別子をエクスポートするには、先頭文字を大文字にして宣言する。
インポートの書式は、「import “パッケージのパス”」。または「import 別名 “パッケージのパス”」の形式でも可で、別名でアクセスすることができる。
インポートしたパッケージ名と識別子の間をドットでつなぐことで、エクスポートした識別子にアクセスする。
インポートしたにもかかわらず未使用の場合、コンパイルエラーとなる。
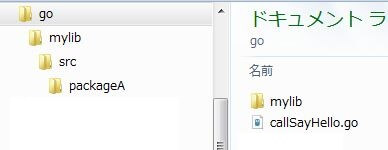
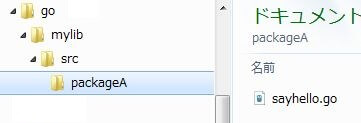
独自パッケージの使用
まず、ディレクトリ構造を決める。
仮にライブラリを格納するディレクトリ名を「mylib」とする。
その直下には必ず「src」ディレクトリを作成する。
最後にsrcの下に任意の名前でパッケージ名でディレクトリを作成する。
callSayHello.goはメイン関数。
●callSayHello.goの内容
1
2
3
4
5
6
| package main
import "packageA"
func main(){
packageA.SayHello("dam")
}
|
sayhello.goは、callされるパッケージのプログラム。頭文字は大文字の「S」である(エクスポートされている)。
●sayhello.goの内容
1
2
3
4
5
6
| package packageA
import "fmt"
func SayHello(who string){
fmt.Println("Hello, " + who)
}
|
次に、mylibをGOPATH環境変数に設定する。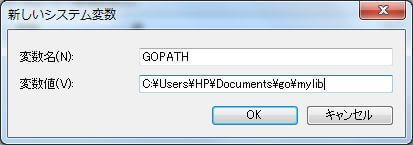
コマンドプロンプトにて「SET GOPATH=”C:\Users\HP\Documents\go\mylib”」を打ち込んでも良い。永続的にはならないが。
準備完了したので実行してみる。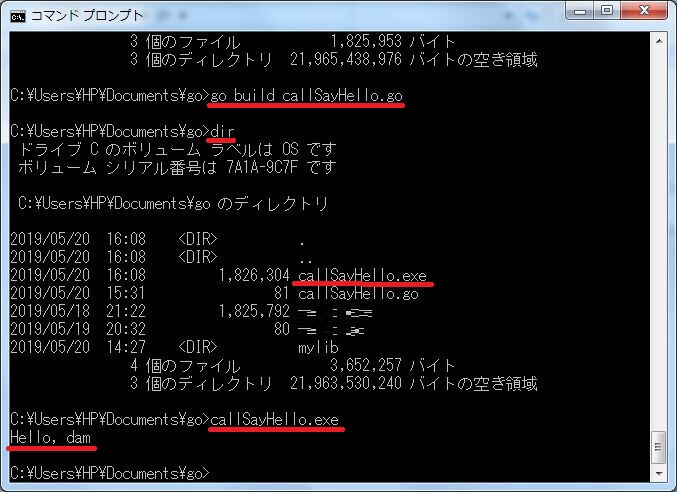
期待どおりに処理された。
Go言語の繰り返し処理、条件分岐、ポインタについて
繰り返し処理
いくつか異なる表記法があるけど、とりあえず2個覚えることとする。一つは無限ループだ。書式は以下。
1
2
3
| for{
// ここに繰り返し処理を書く
}
|
もう一つは、配列の要素を一個ずつ取り出す方法。VBAのfor eachみたいなモノだ。
1
2
3
| for 変数 := range 配列 {
// ここに繰り返し処理を書く
}
|
おなじみのbreak、continueも使える。VBA同様、ラベルも使える。
条件分岐
if文の書式は以下のとおり。
1
2
3
4
5
6
7
| if 条件式A {
// 条件式Aが true の場合の処理を書く
} else if 条件式B {
// 条件式Aが false で、条件式Bが true の場合の処理を書く
} else {
// 条件式A,Bともに false の場合の処理を書く
}
|
switch文とかもあるけど、知らなくても大丈夫。
ポインタ
ポインタ変数とは、アドレスを格納する変数。
ポインタ変数の宣言方法は、型の前に「*」を付けること。
ex) var ptr *int
変数のアドレスを取得するには、変数名の前に「&」を付ける。
ex) ptr = &i
ポインタ変数の指し示すアドレスの値を参照するには、ポインタ変数の前に「*」を付ける。
ex) *ptr
Go言語ではポインタ演算はできない。つまり、ポインタ変数を操作することでポインタ変数に格納されているアドレスとは別のアドレスにアクセスすることはできない。
C言語の復習になるが、関数の引数は、ポインタ渡し(参照渡し)と値渡しがある。
ポインタ渡しはアドレスを渡すので、元の値を編集することが出来る。
値渡しは元の値のコピーを渡すので、元の値は変わらない。
サンプルプログラム
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| package main
import "fmt"
import "strconv"
func main(){
var i int
for{
fmt.Println("i=[" + strconv.Itoa(i) + "]")
if i > 3 {
break
}
i++
}
}
|
strconv.Itoaはint型をString型に変換する。
配列型とかポインタ型のサンプルプログラムは、もう少しいろいろ勉強してから追加する。
Go言語の関数・メソッドについて
関数
1
2
3
4
5
| func 関数名(引数) (戻り値の型のリスト) {
//ここに処理を書く
return 戻り値
}
|
・複数の値を戻り値にすることができる。
・戻り値が1個だけの場合は、「(戻り値の型のリスト)」の丸括弧は不要。
・引数を複数設ける場合、最後の引数を可変長にすることができる。可変長引数の型の前に「…」(ドットを3個)付けることで認識する。ex) func fn(param …int)
・戻り値に変数名を付けられる。この場合、return文に戻り値を書かない。関数呼び出し側で戻り値を受ける変数は、関数宣言部の戻り値の変数名と一致させる必要は無い。
1
2
3
4
5
| func 関数名(引数) (変数 型,変数 型,・・・){
//ここに処理を書く
return //return文には戻り値を書かない
}
|
・名前を持たない関数リテラル(クロージャ)は、他の関数の内側に記述する。C言語で内部ブロックみたいな概念があったと思うけど、それと同じものだろうか。関数リテラルで引数を定義せずとも、関数リテラルの外側の変数にアクセス可能。関数リテラルの使い方は、定義と同時に呼び出す形式にするか、定義をいったん変数に格納してその変数を使う。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| package main
import "fmt"
func main(){
// 円周率
pai := 3.14
// 関数リテラルの定義と呼び出しを同時に行う。定義の末尾で引数の値を与えることが出来る
func(r float64){
// 半径10の円周を出力
fmt.Println(2 * pai * r)
}(10)
// 関数リテラルを変数に格納
f := func(length int, width int){
// 長方形の面積を出力
fmt.Println(length * width)
}
// 関数リテラルを呼び出す
f(13,3)
}
|
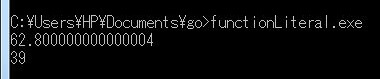 実行結果
実行結果・関数型というものがあるけど、説明を見た感じ、あまり必要性を感じなかったので、Go言語の初心者としてはスルーしておく。
メソッド
型にメソッドを持たせることができる。メソッドの宣言時にレシーバを記載することでどの型に属するかを定義する。
1
2
3
4
5
| func ( レシーバ変数名 レシーバの型 ) メソッド名 (引数) (戻り値の型){
//ここに処理を書く
return 戻り値
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| package main
import "fmt"
type myFloat float64
//myFloat型の変数に対して円面積を出力するメソッドを定義
func (r myFloat) printCircleArea () {
fmt.Println(r * r * 3.14)
}
func main(){
var r myFloat = 10.0
//myInt型の円面積を出力するメソッドを呼び出す
r.printCircleArea()
}
|
 実行結果
実行結果・メソッドのレシーバをポインタにすれば、呼び出し側の値を編集できる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| package main
import "fmt"
type myFloat float64
//myFloat型の変数に対して、レートを掛けた結果を上書きする
func (f *myFloat) multiplication (rate float64) {
*f *= myFloat(rate)
}
func main(){
var f myFloat = 100.0
//myFloat型の円面積を出力するメソッドを呼び出す
f.multiplication(1.08)
fmt.Println(f)
}
|
実行結果は108となり、呼び出し側の変数の値が更新されることが分かる。
・メソッドにも関数型のような使い方があるが、追々勉強するということで、今はスルーしておく。
遅延実行
関数を抜けるときにのみ実行する処理を定義できる。リソース解放などの後処理で使える。
「defer 関数呼び出し」の形式で書く。
1
2
3
4
5
6
7
8
9
10
11
12
| package main
import "fmt"
func main(){
fmt.Println("start")
//遅延実行
defer fmt.Println("後処理")
fmt.Println("end")
}
|
出力結果は
start
end
後処理
となる。
Go言語の構造体について
構造体
1
2
3
4
5
6
7
8
9
| //基本の書式
struct {
//フィールド名
}
//別名を付ける形式
type 別名 struct {
//フィールド名
}
|
・構造体のフィールドごとにエクスポート指定ができる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| package main
import "fmt"
type myStruct struct {
i int
s string
}
func main(){
var x myStruct
x.i = 123
x.s = "Hello, World!"
fmt.Println(x)
}
|
上のサンプルプログラムの出力結果は
{123 Hello, World!}
となる。
匿名フィールドと埋め込み
まずはサンプルプログラムを載せる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| package main
import "fmt"
//親の構造体を定義
type parent struct {
name string
old int
}
//親のメソッドを定義
func (y parent) printField(){
fmt.Println(y.name)
fmt.Println(y.old)
}
//子の構造体を定義。親を引き継ぐ
type child struct {
parent //匿名フィールド。parentのフィールドとメソッドが埋め込まれる(embedded)。
}
//メイン
func main(){
var x child
//フィールドに値をセット
x.name = "dam"
x.old = 50
//フィールド値の出力
x.printField()
}
|
出力結果は、
dam
50
となる。
18行目ではフィールド名を記載せずに、型である構造体名だけを記載している。このように宣言すると、型名をそのままフィールド名として扱える。匿名フィールドという。
匿名フィールドを用いると、匿名フィールドの定義がそのまま適用される(埋め込まれる、embedded)。オブジェクト指向の継承みたいなもの。だから26,27行目のように値がセットできたり、30行目のようにメソッドが実行できる。
構造体の初期化
構造体を初期化するのに構造体リテラルというものを使うと簡単らしい。VBAでメモリのゼロクリアを使うようなもの。これを使うと、個別のフィールドごとに値を設定しなくて済む。だけどねぇ、説明を読んで思ったんだけど、宣言時にゼロ値で初期化されるんでしょ。ゼロ値以外の値で初期化するケースって少ないと思う。
とは言え、使うケースも一応考えられるので、勉強しておく。
●構造体リテラルの書式
1
2
3
| 構造体の型名{フィールド名:値, フィールド名:値, ・・・,}
または
構造体の型名{値, 値, ・・・,}
|
最後の値の後ろにカンマを入れること。入れなくても良い方法はあるが、統一感を出すために、自分の規約としてこのようにしておく。
以下、サンプルプログラム。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| package main
import "fmt"
//親の構造体を定義
type parent struct {
name string
old int
}
//子の構造体を定義。親を引き継ぐ
type child struct {
Eldest bool //長男の場合 true
parent //匿名フィールド。
}
//メイン
func main(){
//初期化方法1
x := child{true, parent{"dam",50}}
//フィールド値の出力
fmt.Println(x)
/* どういうわけか、この方法はコンパイルエラーになる
//初期化方法2
y := child{Eldest:false, parent{name:"mad", old:25}}
fmt.Println(y)
*/
}
|
実行結果は、
{true {dam 50}}
となる。
初期化方法2のコンパイルエラーが解決できないため、跡だけ残して保留しておく。
参考動画:[Go言語の基本] Structs(構造体)を分かりやすく解説Go言語のインターフェース1
インターフェースは、ポリモーフィズ(多態性、多様性)を実現するための機能らしい。
ポリモーフィズとは「共通のメソッドを呼び出すが、オブジェクトによってその機能を変化させる」というものだそうで。
例えば、fmt.Printlnでは、いろんな型を受け付けることができて、型に応じて処理を行い出力するが、これをインターフェースで実現している。
今はまだしっくりと利便性・必要性が理解できていないが、重要な概念・機能らしいので、勉強しておく。
まずはサンプルプログラムから。teratailで質問して得た回答から頂戴する。
●インターフェースを使ったサンプルプログラム
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package main
import "fmt"
type Calc interface{
calculate(a int, b int) int
}
type Add struct {}
func (x Add) calculate(a int, b int) int { return a+b }
type Sub struct {}
func (x Sub) calculate(a int, b int) int { return a-b }
type Mul struct {}
func (x Mul) calculate(a int, b int) int { return a*b }
type Div struct {}
func (x Div) calculate(a int, b int) int { return a/b }
// ひとつでいい
func somethingNiceFunction(c Calc, left int, right int) {
fmt.Println(c.calculate(left, right))
}
func main() {
var a Add
var s Sub
var m Mul
var d Div
// 呼ぶ側も区別しなくていい
somethingNiceFunction(a, 7, 2)
somethingNiceFunction(s, 7, 2)
somethingNiceFunction(m, 7, 2)
somethingNiceFunction(d, 7, 2)
}
|
まず、インターフェースの定義では、メソッドの形式のみ定義する。
そのメソッドの処理は、インターフェースとは別の型のメソッドにて定義する。ただし、インターフェースで定義したメソッドと同じ名前で。
異なる型で同じ名前のメソッドを持たせることで、異なる型に応じたメソッドを同じメソッド名で呼び出すことができる・・・ということになる。
main関数を見てわかるように、異なる型の引数を渡している。Print文と同じだ。
さて、これをインターフェースを使わないとすると、どうなるか。以下のようになるだろう。
●インターフェースを使わない場合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| package main
import "fmt"
type Add struct {}
func (x Add) calculate(a int, b int) int { return a+b }
type Sub struct {}
func (x Sub) calculate(a int, b int) int { return a-b }
type Mul struct {}
func (x Mul) calculate(a int, b int) int { return a*b }
type Div struct {}
func (x Div) calculate(a int, b int) int { return a/b }
// 型によって作り分ける
func somethingNiceFunctionAdd(c Add, left int, right int) {
fmt.Println(c.calculate(left, right))
}
func somethingNiceFunctionSub(c Sub, left int, right int) {
fmt.Println(c.calculate(left, right))
}
func somethingNiceFunctionMul(c Mul, left int, right int) {
fmt.Println(c.calculate(left, right))
}
func somethingNiceFunctionDiv(c Div, left int, right int) {
fmt.Println(c.calculate(left, right))
}
func main() {
var a Add
var s Sub
var m Mul
var d Div
// 呼ぶ側も型によって使い分ける
somethingNiceFunctionAdd(a, 7, 2)
somethingNiceFunctionSub(s, 7, 2)
somethingNiceFunctionMul(m, 7, 2)
somethingNiceFunctionDiv(d, 7, 2)
}
|
名前の異なる関数を追加することになる。関数内のコードは全く同じなのに。
この2つを見比べる限り、インターフェースを使うべきだ。
Go言語の配列について
配列
配列型の書式 ⇒ [長さ] 要素型
長さを取得する ⇒ len(配列)
要素へのアクセス ⇒ 配列[インデックス]
配列の初期化 ⇒ 配列型{初期値1, 初期値2, ・・・}
この配列型の長さを[…]と指定すると、要素数が長さとなる。
●配列のサンプルプログラム
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| package main
import (
"fmt"
"strconv"
)
func main() {
// 配列の宣言と初期化
array1 := [5]float32{}
array2 := [6]int{1,2,3,4}
array3 := [...]string{"One","Two","Three"}
// 初期化内容を出力
fmt.Println(array1)
fmt.Println(array2)
fmt.Println(array3)
// 配列の長さは、len(配列)
fmt.Println("len(array1):", len(array1))
fmt.Println("len(array2):", len(array2))
fmt.Println("len(array3):", len(array3))
// 要素へのアクセスは、配列[インデックス]
fmt.Println("array1[1]:", array1[1])
sum := 0
for _, value := range array2{
sum += value
}
fmt.Println("array2の要素の和:", sum)
for i, value := range array3{
fmt.Println("array3[" + strconv.FormatInt(int64(i),10) + "]:", value)
}
}
|
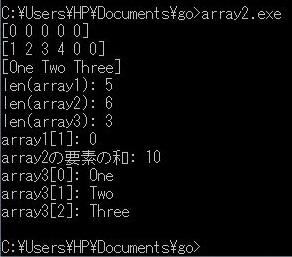 実行結果
実行結果関連ページ