Excel VBAでHTMLソースを取得したときに文字化けしていたら、HTMLドキュメントに書き込む
目次
Webページによってはソースがエンコードされた状態の場合がある
Webページのソース(HTMLテキスト)を取得する。
ブラウザを操作中、例えばExcel VBAでIEを操作中なら、objIE.document.body.outerHTMLで取得できる。特定のTagのinnerTextが欲しければ、objIE.document.getElementById("ほにゃらら").innerTextなどとすればよい。
seleniumを使っている場合でも、似たような感じで取得できる。
しかし、ブラウザを操作する必要がない場合、例えばログイン処理や特定のScript処理を動かす必要がない場合は、別の方法で取得できる。 ブラウザの操作は重くて不安定なので、避けることができるのなら、それに越したことはない。
ただし、この方法を使う場合に注意すべきことは、Webページによっては、取得されるソースがエンコードされたままの場合があることだ。
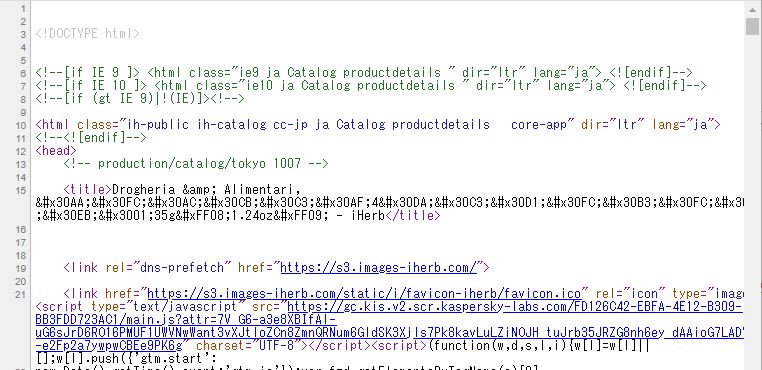
例えば、Yahoo知恵袋のサイトは、ソース自体がデコードされた状態となっている。一方、iHerb(サプリメントのサイト)のソースはエンコードされた状態だ。エンコードされたままかどうかは、ブラウザの開発ツールなどでページのソースを表示させれば確認可能だ。

可読状態にする方法
iHerbのようなサイトのデータを抽出するときは、下記①②のいずれかにより可読状態にする必要がある。
① HTMLテキストをHTMLドキュメントに変換する
② HTMLテキストを直接デコードする(URLデコードではない)
①が簡単だし、簡単なDOM操作ができるという利便性がある。
iHerbのトップページのソースは、次のsampleコードのような感じで取得できる。
| |
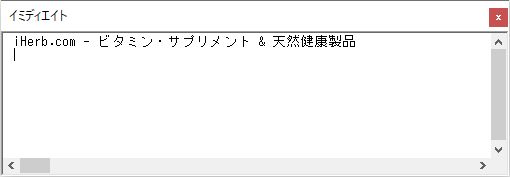
23行目でHTMLドキュメントを生成し、26行目でそのHTMLドキュメントにHTMLテキストを書き込んでいる。この状態でHTMLドキュメントを操作すれば、可読なソースを取得できる。このプログラムを実行すると、29行目でイミディエイトウィンドウに吐かれる内容は、次の図のようになる。文字化けなど起きていないことがわかる。
②は直接デコードする方法。
以下ページにExcel VBAでHTMLデコードする方法が載っているので、一応紹介しておく。
https://stackoverflow.com/questions/6115708/classic-asp-vbscript-convert-html-codes-to-plain-text
一応・・・と断ったのは、動作が不確実だからだ。
私のテストでは期待結果が得られなかった。ソース内の文字コードを把握して、それに応じて変換処理すれば、可読状態になるかもしれない。
しかしそんな七面倒臭いことをするよりも、やはり①の方法を使うのが簡単だ。
参考サイト
◆ HtmlDocument.Write(String) メソッド
https://docs.microsoft.com/ja-jp/dotnet/api/system.windows.forms.htmldocument.write?view=netcore-3.1
◆ HTMLDecode
https://stackoverflow.com/questions/6115708/classic-asp-vbscript-convert-html-codes-to-plain-text