正規表現を使ってCSVの全角半角混在する行を特定する
目次
現在抱えている案件の作業の中で、あるテーブルの住所項目に全角文字・半角文字が混在しているケースにかかるテストが必要となった。まずは全角半角混在しているデータを特定しなければならない。
一番簡単な方法は、CSVに落としてExcelで開き、当該住所項目に対するlen()、lenb()の値を確認することだ。len()=lenb()であれば半角オンリー、len()*2=lenb()であれば全角オンリーと判断できる。上記に該当しなければ、全角半角が混在している。
ただし、Excelがない環境の場合は、別の方法が必要だ。SQLが使えればSQLの正規表現を使ってチェックしても良い。今回はCSVをテキストエディタで開き、正規表現を使った検索機能で目的のデータを特定する。
正規表現のおさらい
このページで出てくる正規表現について簡単におさらいしておく。
| 正規表現 | 内容 |
|---|---|
| ^ | データの先端を示す。処理系が行単位の場合は行頭を示す。 |
| $ | データの終端を示す。処理系が行単位の場合は行末を示す。 |
| [ab] | 文字aまたは文字bにマッチ |
| [^ab] | 文字a,b以外の文字にマッチ |
| [a-z] | aからzの(文字コード上の)範囲内の文字にマッチ |
| * | 直前の文字が 0回以上 繰り返す場合にマッチ |
| (A|B) | パターンAまたはパターンBにマッチ |
| ptn1(?=ptn2) | 直後に ptn2 がある ptn1 にマッチ(先読み肯定グループ) |
先読み肯定グループについては、以下サイトが詳しい。
https://abicky.net/2010/05/30/135112/
問題を単純化する
全角文字・半角文字の混在を特定する正規表現を検討するには、全角文字を表す正規表現、半角文字を表す正規表現を知っている必要がある。問題を単純化するため、全角文字を表す正規表現を文字a、半角文字を表す正規表現を文字bとし、次のCSVデータで考えてみる。
id,data 1,aaa 2,aab 3,aba 4,baa 5,abb 6,bba 7,bbb
目標は、aとbが混在(全角・半角が混在)している行のid値を取得することとする。期待結果は、id=2〜6がマッチして、1と7はマッチしないことだ。
混在する条件は、"ab"または"ba"を含んでいることだ。id値を取得する方法を考慮すると、正規表現は次のようになる。
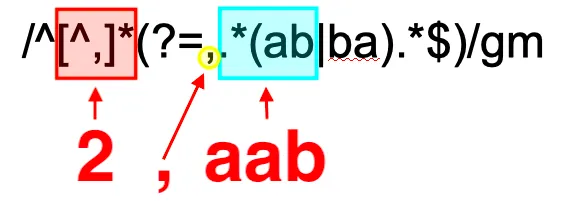
/^[^,]*(?=,.*(ab|ba).*$)/gm
先頭の[^,]*がidに対応している。先読み肯定グループを使って、idの直後に"ab"または"ba"が含まれるidにマッチさせている。
以下は簡単なサンプルデータでテストしたもの。数字に青色が付いている部分がマッチしたことを表している。期待どおり2から6がマッチしている。

例えば、id=2の行と正規表現の対応関係は下図のとおり。
全角半角混在するデータにマッチする正規表現
全角文字、半角文字にマッチする正規表現を考える。
JISコード表を参考に、" "(半角スペース)から"~"(チルダ)まで、 または "。"(半角の句点)から"゚"(半角の半濁点)までを半角文字とする。JISコードに対応する正規表現エンジンがあるか知らないが、半角カナについてはUNICODEでも同じ並びになっているので、JISコード表を文字クラスの範囲指定で使う際の参考にしても特に問題はない。
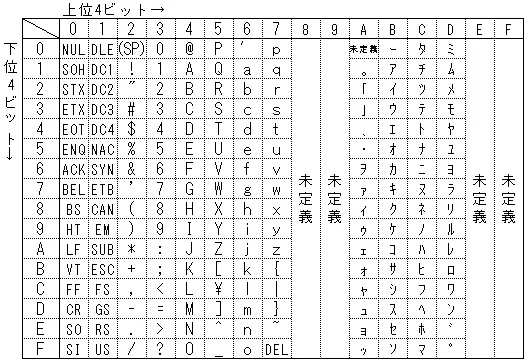
半角文字にマッチする正規表現は次のようになる。左側のハイフンの左に空白(半角スペース)がある(表示されていないのでわかりにくいが)。
[ -~。-゚]
全角文字にマッチする正規表現は、半角文字の否定形。但し単純な否定だと、改行コード\nまでマッチしてしまう。全角文字のみマッチさせたいのに、これでは困る。
よって、改行コードにマッチせず、全角文字にマッチする正規表現は次のようになる。
[^ -~。-゚\n]
全角半角混在するデータにマッチする正規表現は、先に示した正規表現 /^[^,](?=,.*(ab|ba).*$)/gm を加工すればよい。すなわち、a,bをそれぞれ全角文字、半角文字の正規表現に置き換える。
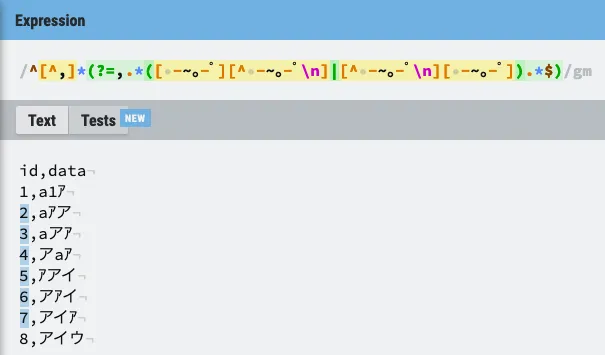
^[^,](?=,([ -~。-゚][^ -~。-゚\n]|[^ -~。-゚\n][ -~。-゚]).*$)
以下は簡単なサンプルデータでテストしたもの。2から7のdataが全角半角混在しており、期待どおりの結果となっている。
さらに実践的なサンプルデータとテスト
次のCSVデータを用意した。今回の目的は番地・建物の列データ(図の赤線部分)に全角半角混在しているレコードを特定すること。No.3,4,7,9がそのようなデータであり、期待どおりにマッチしていることがわかる。
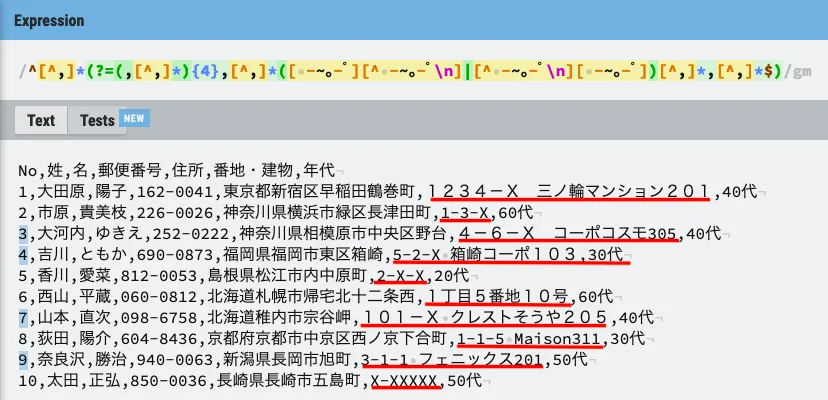
この例では、正規表現は次のようになっている。
/^[^,]*(?=(,[^,]*){4},[^,]*([ -~。-゚][^ -~。-゚\n]|[^ -~。-゚\n][ -~。-゚])[^,]*,[^,]*$)/gm
この正規表現内の(,[^,]*){4}の部分は「,姓,名,郵便番号,住所」に対応している。
実は、この正規表現は少しばかり冗長である。全角文字にマッチさせるための[^ -~。-゚\n]から\nを省いても問題ない。番地・建物フィールド内で改行されていないからだ。もし年代フィールド(右端のカラム)を先読み肯定グループでマッチさせる場合は、行端に改行コードがあるので、\nは省略できないだろう。
参考サイト
正規表現チェックサイトは多数あるが、当記事で使用したサイトは以下。
https://regexr.com/