linuxのxmllintコマンドでXPathの動作確認を行う
目次
サンプルドキュメント
linux の外部コマンド xmllint を用いて XPath のテストを行う。 この記事は XPathの動作確認(Excel VBA編) の linux 編である。
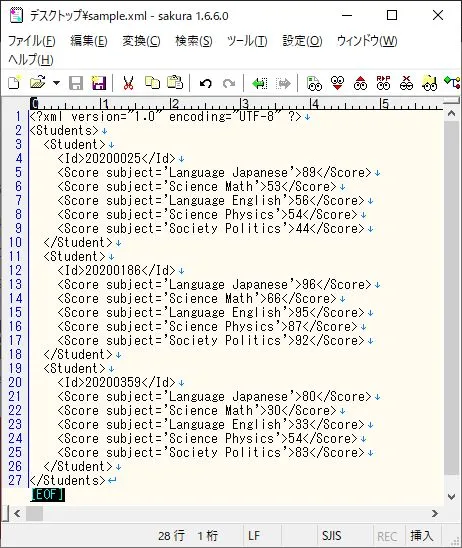
図1のXMLドキュメントファイルをサンプルとする。
構造としては、Studentsの子要素にStudentが複数あり、さらにその子要素にIdとsubject別のScore要素がある。 生徒・科目別の試験点数をイメージして作成したデータだ。
XPathの実装例
フルパス指定
# フルパス指定 $ xmllint --xpath "/Students/Student[1]/Id/text()" sample.xml 20200025
Studentの1番目を指定しているので、20200025 が出力される。 Students の子要素に Student は複数あるが、特に指定がなければ全ての Student に対する要素が出力される(この挙動はVBAの場合と異なる)。
@で属性を指定
$ # 属性値を指定 $ xmllint --xpath "/Students/Student[1]/Score[@subject='Science Math']/text()" sample.xml 53 $ # 「//」でルートから検索1 $ xmllint --xpath "//Score[@subject='Science Math']/text()" sample.xml 53 66 30 $ # 「//」でルートから検索2 「*」ですべてのタグが対象 $ xmllint --xpath "//*[@subject='Science Math']/text()" sample.xml 53 66 30
subject属性が「Science Math」と一致する要素がヒットする。
containsの使い方
$ # containsの使い方1 $ xmllint --xpath "//Score[contains(@subject, 'Politics')]/text()" sample.xml 44 92 83 $ # containsの使い方2 $ xmllint --xpath "//Id[contains(text(),'202003')]/text()" sample.xml 20200359
「containsの使い方1」では属性に対して contains を適用、 「containsの使い方2」ではテキストノードに対して適用している。
「containsの使い方1」では、subject属性に「Politics」という文字列が含まれるScore要素がヒットする。
「containsの使い方2」では、テキストノードに「202003」という文字列が含まれるID要素がヒットする。なお、テキストノードに改行や空白が含まれているとヒットしないことがある。その場合は例えば //Id/text()[contains(.,'202003')] のように少し書き方を変えてみること。
position で要素の位置を指定
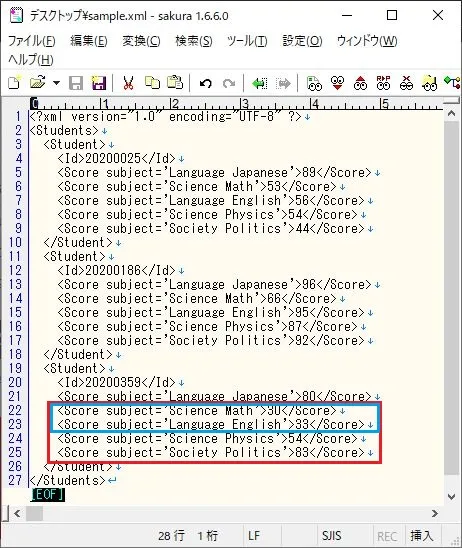
$ # 要素の位置を指定1 $ xmllint --xpath "//Score[contains(@subject, 'Lang')][position()=2]/text()" sample.xml 56 95 33 $ # 要素の位置を指定2 $ xmllint --xpath "//Score[contains(@subject, 'Lang')][2]/text()" sample.xml 56 95 33 $ # 要素の位置を指定3 $ xmllint --xpath "//Student[3]/Score[position()>=2][position()<3]/text()" sample.xml 30 33
「要素の位置を指定1」では、まずsubject属性値に文字列「Lang」が含まれる要素がヒットする。テストデータを見ればわかるが、6個の要素がヒットする。この6個のうち、positionで指定された2番目が最終的にヒットする。
「要素の位置を指定2」は「要素の位置を指定1」の省略形。
「要素の位置を指定3」では、まず3番目のStudent要素の子要素Scoreのうち、2番目以上の要素 (図の赤色枠) がヒットする。その赤枠内での3番目未満 の要素 (図の青色枠) が最終的にヒットする。
sum, countの使い方
$ xmllint --xpath "//Student[sum(Score/text()) div count(Score) > 80]/Id/text()" sample.xml 20200186
当記事のテストデータは、生徒・科目別のテスト点数をイメージして作成したものだが、上記コードでは、平均点が80点以上の生徒のIDが取得される。
まず、sum(Score/text())について。 Studentの子要素にはsubject別に5個のScore要素があり、さらに各Score要素のテキストノードに得点が表記されている。このテキストノードの値を全て集計している。
次に、count(Score)では、Studentの子要素Scoreの数をカウントしている。 div は除算を示す演算子だ。
結局、合計点数を科目数で割り算して平均値を算出し、計算結果が80以上のStudentを特定している。 さらに、その特定されたStudentの子要素Idを取得している。
and, or の使い方
$ # and の使い方1 $ xmllint --xpath "//Student[Score[contains(@subject,'Physics') and text() >= 80]]/Id/text()" sample.xml 20200186 $ # and の使い方2 $ xmllint --xpath "//Student[2]/Score[position()>=3 and position()<5]/text()" sample.xml 95 87 $ # or の使い方 $ xmllint --xpath "//Id[contains(text(),'202001') or contains(text(),'202002')]/text()" sample.xml 20200186
「and の使い方1」では、物理(Physics)の点数が80点以上の生徒のIDが取得される。
「and の使い方2」では、2番目のStudent要素の子要素Scoreのうち、3番目以上5番目未満の要素が取得される。上で説明済みのpositionのコード例と比べてほしいが、Score[position()>=3 and position()<5] と Score[position()>=3][position()<5]では結果が異なることに注意。
following-sibling の使い方
$ xmllint --xpath "//Student[Id='20200359']/Score[3]/following-sibling::Score/text()" sample.xml 54 83 $ xmllint --xpath "//Student[Id='20200359']/Score[3]/following-sibling::Score[1]/text()" sample.xml 54 $ xmllint --xpath "//Student[Id='20200359']/Score[3]/following-sibling::Score[2]/text()" sample.xml 83
following-sibling は、基点より後にある兄弟要素を検索する。
//Student[Id='20200359']/Score[3]でヒットした要素を基点として、その後方の兄弟Score要素が検索される。なお、自分自身は含まれない。
following-sibling::Scoreの末尾に position 指定がない場合は、ヒットした要素グループの全ての要素が取得される。 position 指定がある場合は、基点から後方に向かって position 番目の要素が取得される。
preceding-sibling の使い方
$ xmllint --xpath "//Student[Id='20200359']/Score[3]/preceding-sibling::Score/text()" sample.xml 80 30 $ xmllint --xpath "//Student[Id='20200359']/Score[3]/preceding-sibling::Score[1]/text()" sample.xml 30 $ xmllint --xpath "//Student[Id='20200359']/Score[3]/preceding-sibling::Score[2]/text()" sample.xml 80
preceding-siblingは、基点より前にある兄弟要素を検索する。
//Student[Id='20200359']/Score[3]でヒットした要素を基点として、その前方の兄弟Score要素が検索される。なお、自分自身は含まれない。
preceding-sibling::Scoreの末尾に position 指定がない場合は、ヒットした要素グループの全ての要素が取得される。 position 指定がある場合は、基点から前方に向かって position 番目の要素が取得される。
参考サイト
XPathについて初心者の場合は、まず以下サイトでイメージをつかむことをお勧めする。
https://www.techscore.com/tech/XML/XPath/index.html/
https://qiita.com/rllllho/items/cb1187cec0fb17fc650a